FOOM 无堆栈个例聚类
FOOM 问题由于采样的缘故,大部分个例上报是不包含堆栈信息的,导致很多问题无法定位。为此 Bugly 对无堆栈问题提供新的聚类方式,通过其他特征,为无堆栈个例寻找相似的“有堆栈 issue”并将其归类其中。
FOOM 个例特征
能够提供一个 FOOM 个例最有效特征的信息,自然是其内存分配信息,其可以直接指向内大量内存分配行为出自哪些业务逻辑。目前 Bugly 默认聚类 FOOM 个例问题也是通过提取分配堆栈的特征实现的。 但是由于堆栈记录使用采样方式,并非所有的个例都包含内存分配堆栈信息。因此对于无堆栈的个例,则无法使用堆栈信息作为特征使用了。(Bugly 默认将所有无堆栈的个例聚类到一起,形成了“无堆栈问题“ issue。)
关于 FOOM 个例内存分配堆栈的信息,可以参考 FOOM 个例详情-堆栈分配详情。
除堆栈信息以外,对于 FOOM 个例,Bugly 还采集提供了 VMMAP 信息。VMMAP 包含了当前内存使用的主要情况及其对应的内存类型。由于 VMMAP 的采集是主动获取,采集频率可控,且可以在子线程独立进行,性能开销很小,不影响 App 的业务逻辑正常执行,因此可以全量开启,对所有的 FOOM 问题上报都提供此信息。
相较于内存分配堆栈,VMMAP 所提供的信息量更少,对于业务明确定位问题的帮助自然也没有内存分配堆栈大。关于 FOOM 个例的 VMMAP 信息,可以参考 FOOM 个例详情 - VMMAP。
事实上,分配堆栈信息在采集时,包含了内存的类型,如 VM_MEMORY_MALLOC 和 VM_MEMORY_COREGRAPHICS_DATA 等分配类型信息。该信息与 VMMAP 中的 user_tag 一一对应的。某种程度上,分配堆栈信息是对 VMMAP 信息的更详细补充。
例如如下个例中,VMMAP 中内存占用较多的为 VM_MEMORY_CGIMAGE 类型的内存:
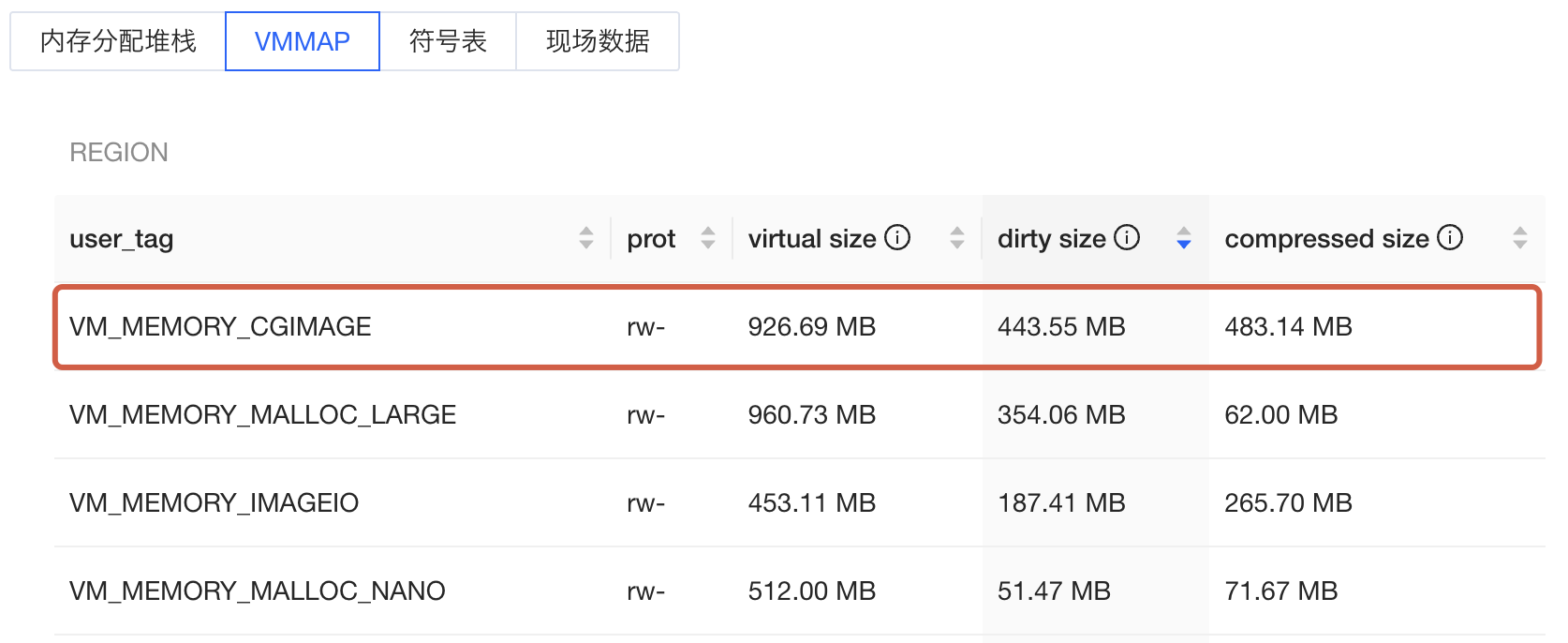
可以在内存分配堆栈中找到对应的类型下的详细分配堆栈信息。
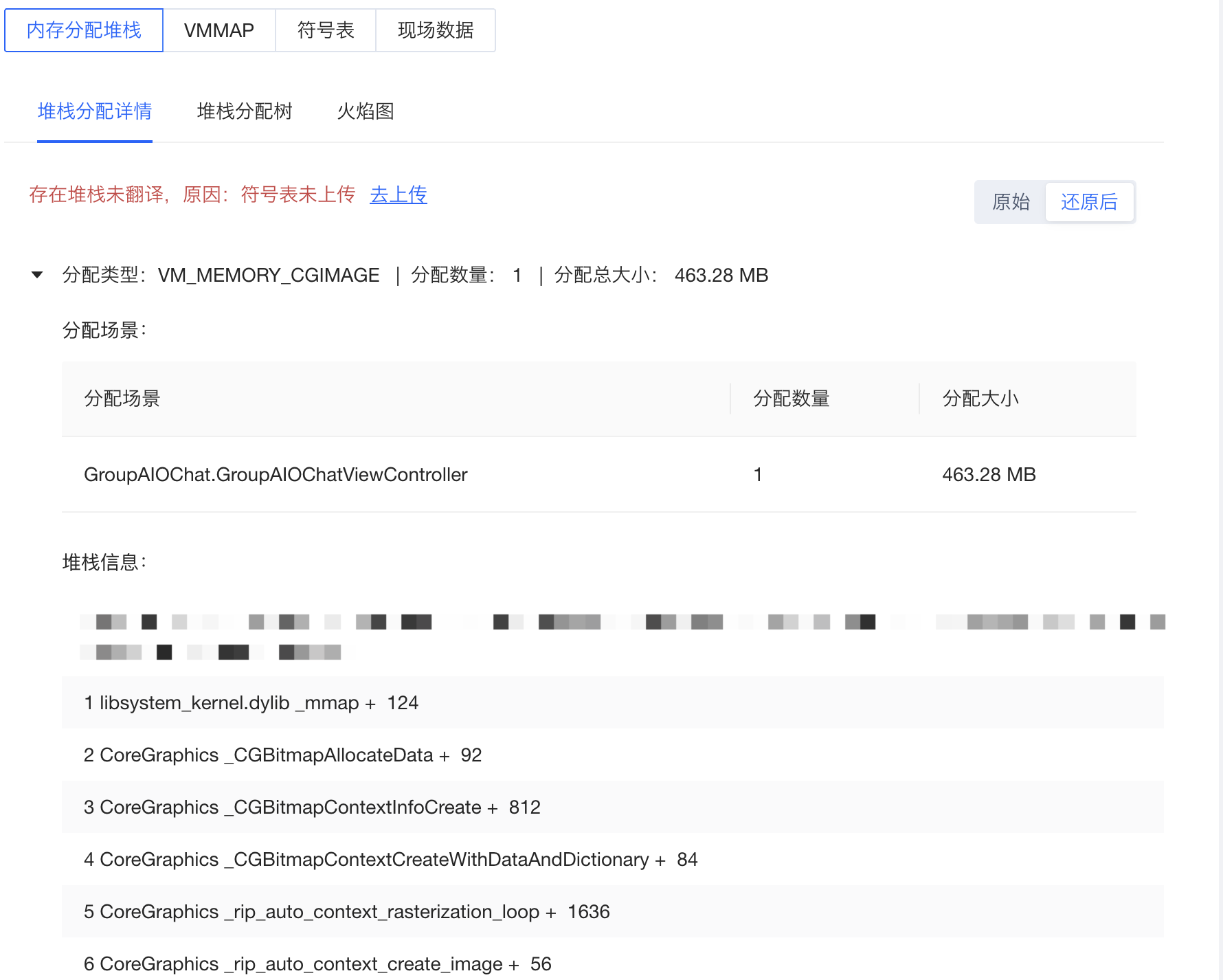
限于 VMMAP 信息只能区分到内存类型和大小等信,对于业务直接定位问题远远不够,一致作为补充数据提供,故一直使用内存分配堆栈进行问题聚合。
无堆栈问题聚合
虽然 VMMAP 信息不足以定位问题,但由于其本质还是提供了内存使用情况的概况信息,还是具有一定特征的。因此我们可以考虑利用 VMMP 的特征将无堆栈个例关联到“有堆栈 issue” 中,实现为无堆栈个例寻找相似的有堆栈 issue 并将其归类的目的。
但由于 VMMAP 信息是更为抽象,因此与使用内存分配堆栈这种更详细数据提取特征进行的聚类的“有堆栈 issue”必然不是一对一的关系。因此在实现该关联的实现中,势必会有一定的取舍,做到尽可能关联到相似问题中。
VMMAP 特征分布
通过统计“有堆栈 issue” 中所有个例的 VMMAP 特征的数量分布情况,发现其数量分布会集中在其中的一个特征中。

此处展示的数据仅为说明数量分布情况的示例,并非真实数据。
这样的数据分布并不意外,正如前所述 VMMAP 数据和堆栈数据二者本身就存在一定的关联。 此分布结果也可以更好的佐证以下结论:
- VMMAP 特征与堆栈特征信息存在着明显关联;
- 可以将明显集中分布的 VMMAP 特征作为该 issue 的一个备选特征,为无堆栈问题提供聚类的依据。
通过统计 VMMAP 特征的数量分布情况,为无堆栈个例匹配其 VMMAP 特征数量分布最集中的“有堆栈 issue”将其关联并归类。从而最大概率的将无堆栈问题与有堆栈问题进行关联,这样可以为无堆栈问题找到最有可能是同类问题的有堆栈问题。
无堆栈问题特征匹配
为此,Bugly 通过如下过程,为无堆栈问题匹配其最有可能是同类问题的有堆栈问题:
- 通过离线计算,统计出线上现存所有“有堆栈 issue” 的 VMMAP 特征数量分布情况;
- 对所有无堆栈个例(包括线上现存和后续上报的数据)提取对应的 VMMAP 特征;
- 从统计出的特征数量分布情况中,找出包含无堆栈个例的 VMMAP 特征匹配的所有“有堆栈 issue”中数特征数量最多的 issue,并将其归类为该 issue;
- 对于新上报的有堆栈个例,使用堆栈特征归类的同时更新其对应分类中的 VMMAP 特征数量分布数据;
因该算法需要使用已数据中的数量分布关系来实现关联,因此需要对线上已有数据进行离线处理,以获得有效的分布数据。理论上当数据量越大,其关联的准确性也越高。同时由于线上问题会随着业务的变化而发生变化,因此需要确保数量分布数据保持同步的更新。
通过上述方式关联并归类的无堆栈个例,因为其收集的诊断数据不足,虽然无法确定其一定是同一问题,但是当可以找到最大概率是同一问的 isseu,在面对大量无堆栈问题的情况下,可以找到其相似问题来优化解决。
事实上,通过初步统计,使用 VMMAP 特征关联后,同一 FOOM 中的场景信息等都会明显的集中在一起,从侧面验证了该方案的有效性。
无堆栈问题聚类使用
无堆栈问题聚类本质只是对 Bugly 平台已有数据的重新聚类处理,因此不需要业务升级 SDK 或配置更便可以使用。
在 iOS FOOM 问题列表中,将“无堆栈问题聚类方式”选择为“嵌入聚类”即可启用该分类方式,之后原来的“无堆栈问题” issue 中的所有个例会通过上述方式完成新的分类。
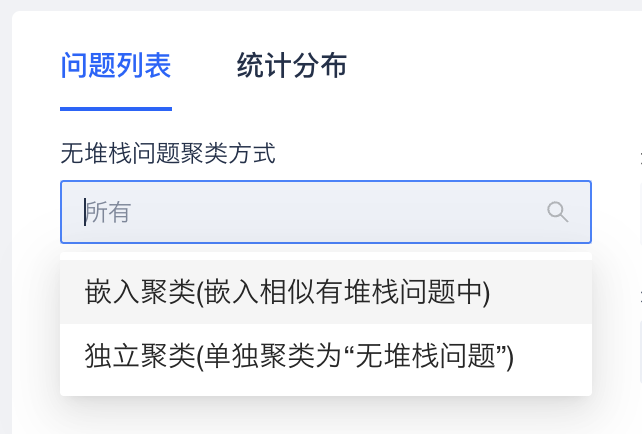
同时,为了方便在问题详情中快速找到“有堆栈”问题,在详情分析的筛选框中增加了“有无内存分配堆栈”的筛选条件,可以通过该条件,快速找到有堆栈的问题,进行分析和定位。

其他问题
1. 使用无堆栈问题“嵌入聚类”的方式,是否可以将所有的无堆栈问题都找到对应的“有堆栈 issue”?
并非如此,正如前所述,随着业务的变化,会有新的 FOOM 问题产生,对于这类问题在其刚产生时,可能找不到与之相似的有堆栈问题(找不到对应的 VMMAP 特征),其还是会被聚类为“无堆栈问题”。
2. 为何使用无堆栈问题“嵌入聚类”的方式,issue 详情中没有有效的“有堆栈个例”?
按照上述方式聚类后,对于非“无堆栈问题” issue 中,一定存在有堆栈个例,但是有时用户筛选的时间范围太小,导致在该时间范围内未找到有堆栈个例,可以适当的扩大时间范围条件,便可以找到对应的“有堆栈个例”。同时也建议在使用该方式聚类时,尽可能的选择较大的时间范围。
3. 发现同一个 issue 中的个例堆栈等信息的关联度不高,是什么原因?
因为对于有堆栈问题的聚类是建立在堆栈及特征提取的基础上实现的,本身确实存在一定不准确的情况。而“嵌入聚类”的方式是基于有堆栈问题聚类结果上进行的,因此若是前者不准确的情况下,后者自然也存在不准确的情况。对于前者不准确的情况,业务可以通过简单的配置来影响特征提取,具体操作方式可以参考聚类调整。
4. 堆栈记录到的内存分配占峰值内存的比例很低,没有参考价值是怎么回事?
此时可以看看 VMMAP 中的内存使用情况,若内存占用主要发生在VM_MEMORY_MALLOC_NANO 或 VM_MEMORY_MALLOC_TINY,VM_MEMORY_MALLOC_SMALL 中,则说明内存占用都是小对象分配导致的。按照 Bugly Malloc Logger 的默认策略,是不会对该部分分配进行采集的,此时可以参考FOOM 动态配置调整&内存图辅助的方案进行进一步的深入分析。
小结
无堆栈问题是 Bugly FOOM 内存监控方案使用采样策略造成的,理论上业务只需要关注有堆栈问题即可,但在实际实践中发现,对于查询特定反馈时,可能会遇到无堆栈的情况,此时就很难进一步定位问题。为此 Bugly 结合数据特征分析,采用了上述方式将其尽可能的关联在有堆栈问题中,以便业务定位同类问题。
若业务在使用过程中有其他疑惑或建议,欢迎反馈到 Bugly 团队,与我们一起交流改进平台工具。