ANR (Deadlock)
ANR (Application Not Responding), 它是 Android 系统中的一个术语,用于描述应用程序在一段时间内未能响应用户输入的情况。在 iOS 系统中,表现为因为错误码为 0x8badf00d 的 SIGKILL 。
在 Bugly 平台中,因为其本质为同一种异常表现,故这里统称为 ANR,方便平台和开发者统一概念。
ANR 指标
ANR 问题的本质是主线程卡顿,导致 App 响应用户输入超时,触发系统 WatchDog 机制,从而杀死进程。Bugly 通过检查主线程 Runloop 执行周期,判定主线程是否发生了卡顿,对于超过阈值(默认 5s)的卡顿,则标记为可能发生 ANR 事件。结合 App 进程退出判定,若进程最后退出状态时,依然为可能发生 ANR 事件的状态,则判定上一次进程退出为 ANR。
综上,Bugly 将 App 前台运行期间进程被 SIGKILL 时,处于长卡顿状态的退出场景,判定归类为 ANR 异常。
注意: 由于 SIGKILL 信号是直接杀死进程,不会有任何信号或通知到进程内部,因此 Bugly 将已知的退出(例如用户手动杀死进程、其他 Crash等退出)排除后的退出当作 SIGKILL 处理,这一定的处理上,与 FOOM 判定方式类似。
为了方便衡量 ANR 事件的严重程度,Bugly 提供了 ANR 指标 -- ANR 率 -- ANR 退出次数与进程启动次数的比值。同时加入了从设备角度和用户角度衡量的指标,即设备 ANR 率和用户 ANR 率,二者均是有设备 ID 和用户 ID 去重后计算所得。
- ANR 率 = 退出次数 / 启动次数
- 设备 ANR 率 = 设备 ID 去重后的退出次数 / 设备 ID 去重后的启动次数
- 用户 ANR 率 = 用户 ID 去重后的退出次数 / 用户 ID 去重后的启动次数
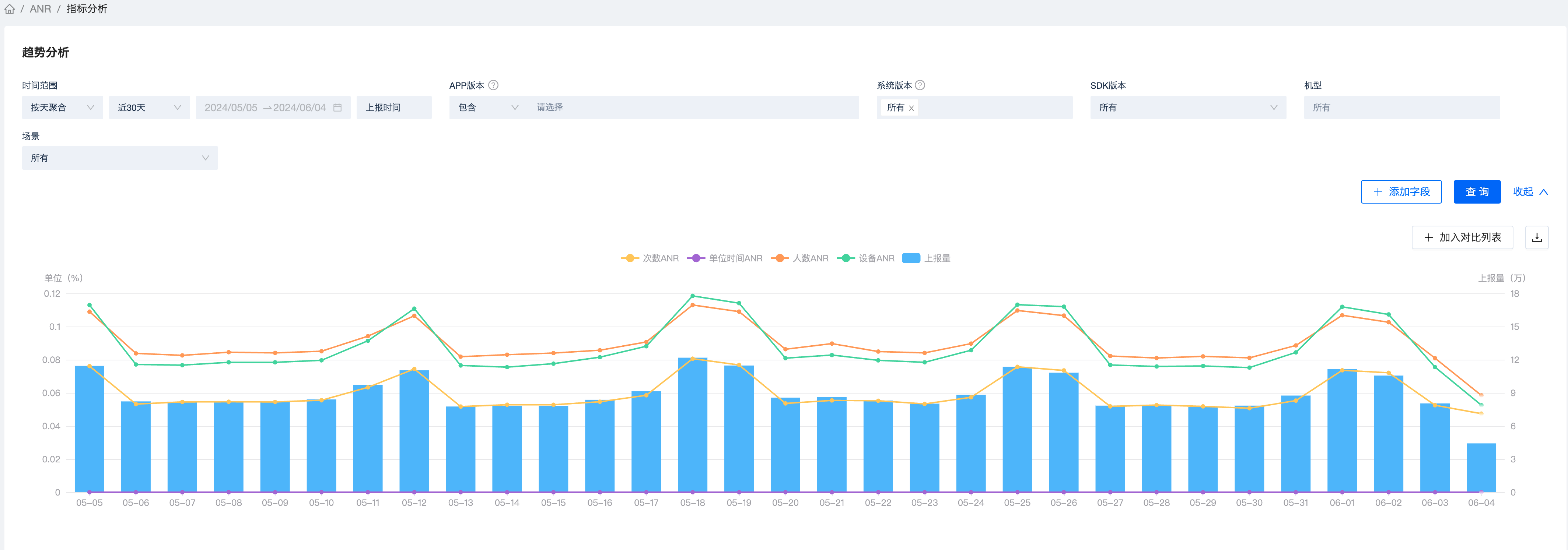
与其他指标分析类似,支持按照不同的条件进行筛选分析不同条件下的指标变化和对比。
ANR 诊断信息
如 ANR 指标所述,Bugly 根据主线程 Runloop 执行情况来判定是否发生了 ANR。在监控主线程执行时间的同时,Bugly 会对主线程的执行调用栈进行周期性采样,如此以来在发生卡顿或 ANR 的时候,便可以收集到对应期间的具体执行逻辑。
Bugly 默认会以 60次/秒 的频率对主线程的执行栈进行采样,在发生卡顿或者 ANR 时,将之前采集到对应时间的调用栈作为对应的诊断数据一并上报到后台进行调用栈还原和分析。因此 Bugly 可以提供卡顿的具体耗时方法和执行情况。
限于采样频率的缘故,Bugly 计算出来的方法执行耗时一定是采样间隔的整数倍,存在一定的误差。对于默认 60Hz 的采样频率,其误差应为 ±16ms。
ANR 问题列表
Bugly 将上报的 ANR 个例按造成其异常的调用栈的特征进行聚类,将同类问题作为一个 issue 进行统计,方便业务跟进和定位问题。对于每一个 issue,问题列表中会统计其影响设备数、最近上报时间等信息,与其他问题列表的表现类似。
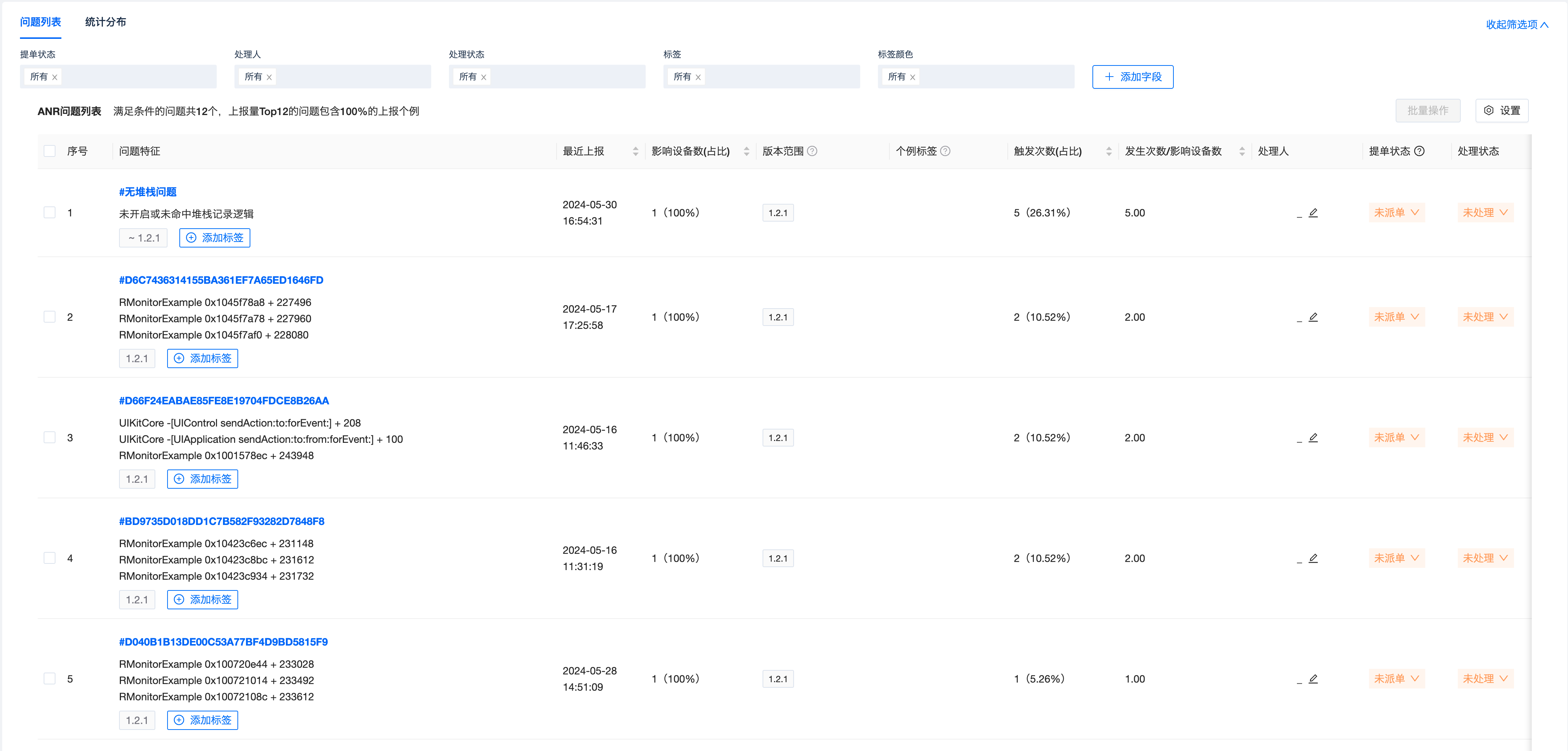
调用栈特征提取
如前所述,Bugly 会将造成 ANR 的调用栈上报到后台。为了有效聚类个例问题,Bugly 通过提取关键耗时方法,使用关键耗时方法中的前三层函数作为其特征。
由于调用栈采集的为连续时间内的执行情况,因此按照栈底往上,将相邻相同的帧进行合并,便可以将调用栈作为调用树,其中每个节点表示对应方法的执行耗时。
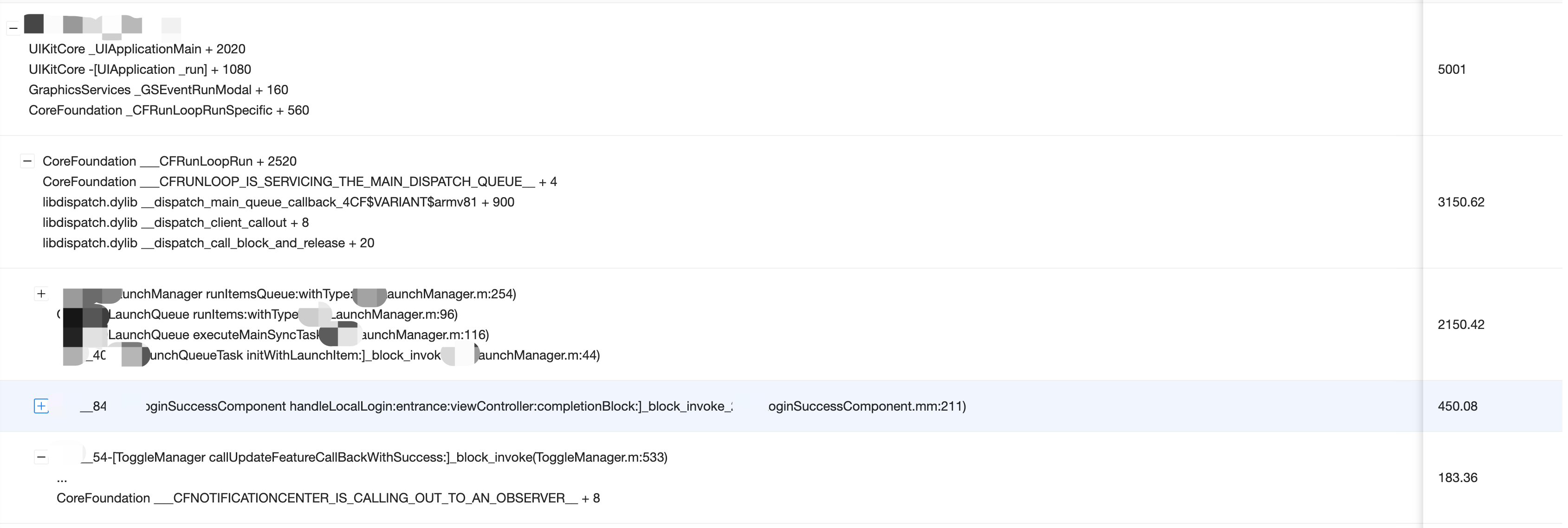
在堆栈树中,找到耗时较大的一条路径,作为关键耗时方法,之后提取这条路径中的前三层作为其特征进行聚类。
问题列表 -- 无堆栈问题
在问题列表中,会存在一个特殊的 issue 类,其没有关键耗时特征栈 -- “无堆栈问题”。无堆栈问题的出现是由于 Bugly 采样机制导致的。
对于没有开启堆栈采样的个例,由于其无法提供对应的诊断堆栈信息,但在某些情况下,需要查看对应的用户或设备的 ANR 发生情况,故此问题列表中会展示这部分发生 ANR 的个例,并将其都归类在“无堆栈问题”中。
在堆栈采样率开启到 100% 时,依然会有无堆栈问题上报,属于 Bugly 已知问题,在早期版本中表现更加明显。其是因为 SDK 在堆栈持久化时有一定延迟,导致堆栈还未持久化,进程就已被杀导致,Bugly 目前这在逐步优化以减少此类情况的出现。
ANR 个例分析
个例分析是解决 ANR 问题的重要依据,其提供了造成 ANR 的详细原因,提供有效的诊断数据定位 ANR 问题。通过问题列表中的 issue 进入到其对应的个例列表中,与其他问题列表及个例分析类似,同样提供基本的个例信息,例如发生时间、上报时间、用户/设备ID 等,同时也提供对应的筛选条件。下钻分析也是类似,提供了该 issue 下的个例上报趋势、版本分布等等信息,此处不再赘述。
个例问题的消息详情中,提供了出错堆栈、全线程堆栈、操作日志、符号表、现场数据等信息,其中操作日志、符号表、现场数据等都与其他问题的消息详情一致,此处不做多余赘述,重点解释出错堆栈和全线程堆栈。
1. 出错堆栈
出错堆栈即为前述中提到的周期性采集的主线程调用栈,提供了三种展示方式:时间片、堆栈树、火焰图。这三种方式都是用同一份数据生成的,只是以不同的方式呈现,方便查看。
- 时间片:采集的原始数据,以采集的时间区间的顺序依次展示,其中
TimeSlice: xx~xx标识对应的采集区间内的调用栈详情,点击查看即可。在采集和上报时,会将相同时间片的相同调用栈进行合并,展示时亦是如此。例如 TimeSlice: 10~20 表示采集区间为 10~20 时刻都是一样的调用栈,即这里一直在执行同样的逻辑;这里的时间区间时相对值,表示最后采集时间范围内的第几次采集,因上报堆栈均为判定疑似 ANR 发生的时刻最近 5s 内采集,序号有远及近的表示对应的采集周期,例如 1 表示 ANR 判定发生那一刻时保留的最早的一次采集数据,以此类推。
- 堆栈树:堆栈树为更为有效的一种表现方式,其通过对时间片数据从栈底依次往上聚合,生成的调用树,其每一个节点表示对应方法的执行时间,可以更加直观的发现卡顿方法及其时间;
- 火焰图:堆栈树的图形化表示方式;

出错堆栈直接展示了卡顿的时间和对应的方法,对于一般问题而言,基本可以定位到导致异常的方法。但出错堆栈只包含主线程的状态,但有些 ANR 问题可能是由于主线程等待锁导致的,此时需要知道锁被何处持有,才能更好的定位具体原因。此时就需要用到全线程堆栈了。
2. 全线程堆栈
全线程堆栈是在判定疑似 ANR 时捕获的所有线程的调用栈,包括主线程自己,其目的是方便业务查看锁竞争的问题。
一般而言,若主线程因为锁等待造成卡顿,按照调用栈找相同的锁使用逻辑,可以查看其他线程是否有持有对应锁或等待相同的锁,便可以知道是否发生了死锁或长时间的锁等待等问题。